In this post, we will see how Amazon CloudFront can deliver content out of Azure blob storage.
These are the topics touched throughout the post:
- Azure Blob Storage basics
- Amazon CloudFront basics
- Amazon Route 53 basics
- Hands-on to implement the delivery of data using Amazon CloudFront
This is how various services mentioned in the post interact with each other:
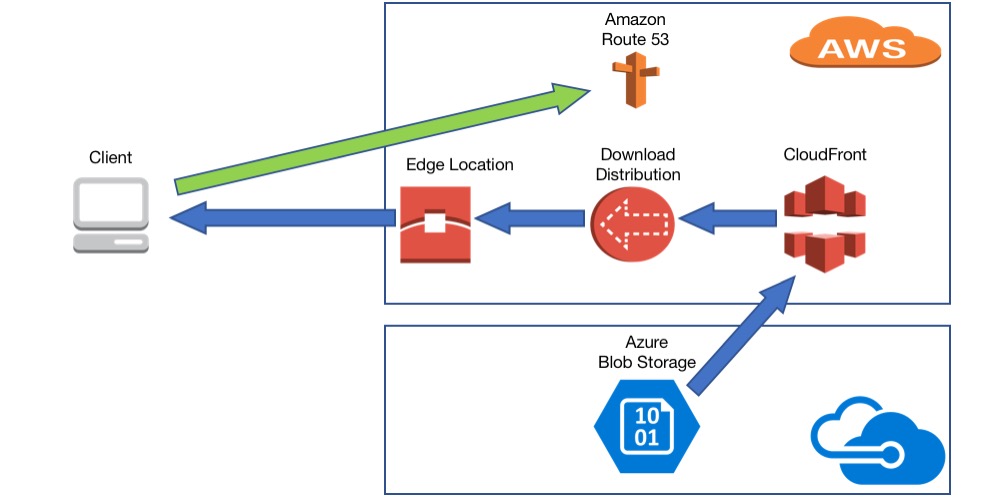
Azure blob storage is a service that stores unstructured data in the cloud as objects or blobs. The data stored in this way can be anything from pictures, documents to video files.
Blobs are stored in containers which one can consider simple directories.
The endpoint for a blob storage is “http://<storage_account>.blob.core.windows.net”, followed by the container name and blob name.
Data stored in this way can be accessed directly using links like “http://<storage_account>.blob.core.windows.net/container_name/blob_name”.
Amazon CloudFront is a service that allows faster distribution of web content with the help of edge locations.
These edge locations have the advantage to be spread across the globe to increase the chances to have one edge location as close as possible to clients.
When a client requests data, it is redirected to the edge location with the lowest latency, hence improving the speed at which the content is available to clients.
Amazon CloudFront uses a distribution that tells CloudFront which origin servers to use to provide data to clients.
Origin servers are placeholders for the data that it meant to be available to clients.
If the data is not available on the edge location, CloudFront will request the data from the origin servers and once the very first bytes of the data arrives to CloudFront, they are sent to the client.
If the data is not available on the edge location, the first client requesting the data will not see any improvement of the transfer.
However, the subsequent clients requesting the same data from the same edge location will benefit from the fact that data is already in the edge location cache.
The CloudFront distribution link is something similar to “http://<subdomain_name>.cloudfront.net”, followed by the filename of the interesting data. The user cannot configure the subdomain name.
Amazon CloudFront service is similar to Azure CDN service.
One reason for which one might consider this aproach of using storage from Azure and distribution services from AWS is migration from one cloud provider to another cloud provider without a hard cut of services during migration.
Amazon Route 53 is the DNS service that Amazon provides to its customers that allows to work with DNS zones.
For testing purposes, when the client will access a valid domain name(awswork.com), he/she will be redirected to CloudFront distribution link.
Now that the services required to implement this solution were covered, it is time to see how to implement the solution.
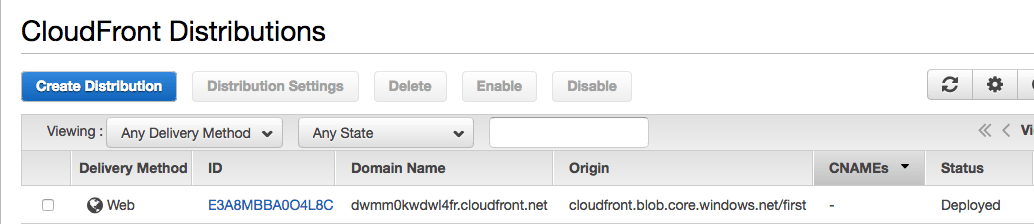
Obviously, all starts from the data stored in Azure in two containers.
This is the first container that has two files: one .html file and one .jpg file:
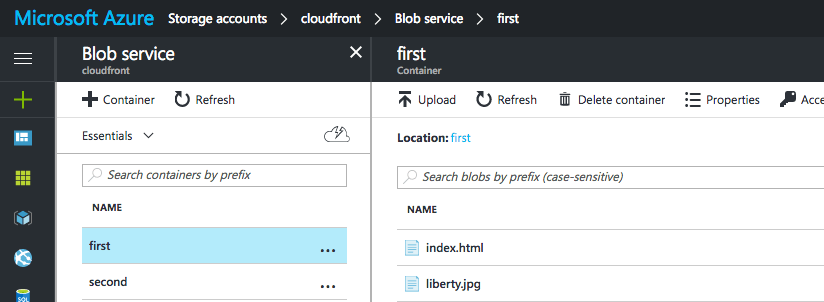
The second container has only one .htm file(pay attention to the extension as it will make a difference at one point in the post):

As expected, each of these files are publicly available and this is the content of index.html from container “first”:

And this is the content of index.htm:
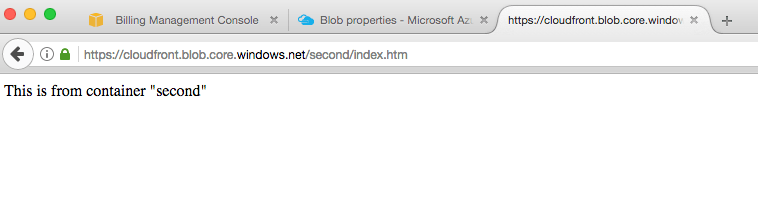
The files are accessible using the standard path based on the container name and blob name.
The content is just a little bit different so it can be easily known which index file is viewed.
It is time to move to AWS Management Console and create the CloudFront distribution.
Therefore, in the CloudFront section, “Create Distribution” will start this process:
The distribution will be a web one:
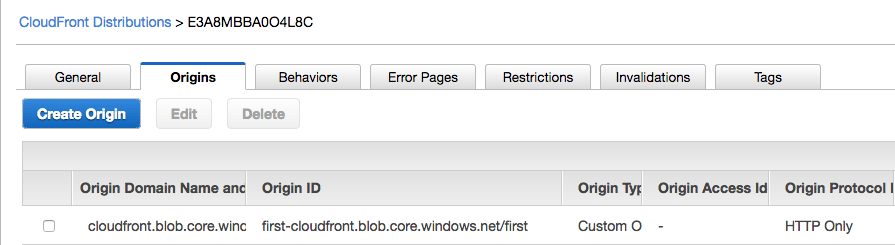
In the distribution initial configuration, only the first container from Azure storage will serve files to the CloudFront distribution. Observe that the origin path references the container “first”:

The distribution deployment will take 10-15 minutes and once the status is deployed, it can be used to retrieve data from the Azure storage.
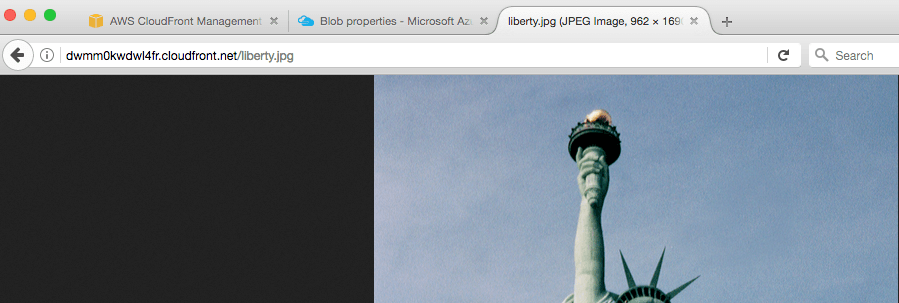
To access the blobs from Azure through CloudFront, the distribution domain name, dwmm0kwdwl4fr.cloudfront.net, will be used followed by the name of the file:
This is one example. Observe that the container name is nowhere referenced. This is because CloudFront looks directly /first path:

To instruct CloudFront where to look for data will require additional origin.
Create another origin from the “Origins” section of the CloudFront distribution:
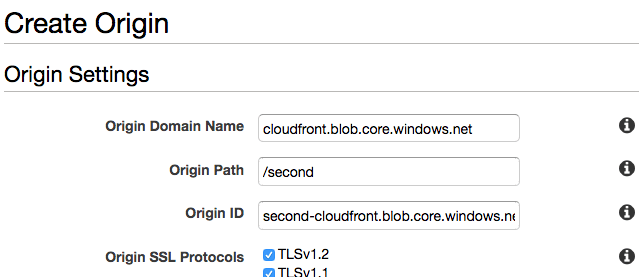
For the second origin, the origin domain name will be the same, but the origin path will point to second container:
Now, CloudFront has two places from where it can request data:
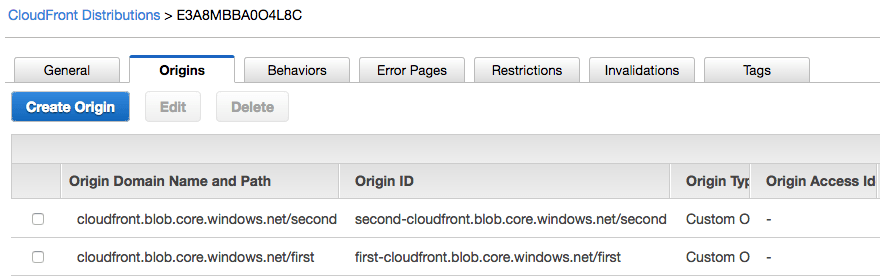
As mentioned earlier, CloudFront will be configured in such a way that based on the files requested by client, it will look on the first container or the second one.
To achieve this granularity, additional behaviors must be added. Currently, any(*) file will be looked for in the first container:

What is going to happen is that for any .htm files, CloudFront will be instructed to look in the second container(observe the origin):
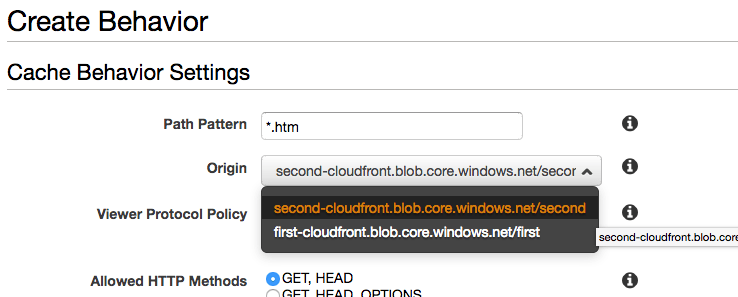
And for any .html files, CloudFront will look in the first container:

And the result is below. One important thing about CloudFront behaviors is the order/precedence. If the default path pattern(*) takes precedence, then CloudFront will look only in that origin. If the file requested is in another origin, then CloudFront will return a not found page.
In this case, .html pattern has to take precedence over .htm because .htm covers .html, but vice-versa doesn’t hold true. If .htm pattern had precedence 0, then both .html and .htm files will be looked in the first container:
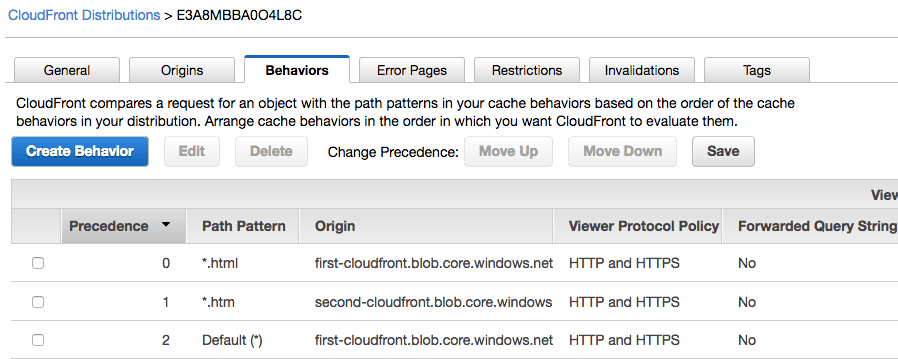
Let us use CloudFront to retrieve an .htm file, in this case, index.htm. Because the pattern doesn’t match the behavior with 0 precedence, next pattern is processed and it is a match:

For any other file(*), the first container will be used as origin for CloudFront. Here CloudFront did not match the first and second behavior pattern and felled back to the default behavior:
Amazon Route 53 will be used to convert the CloudFront distribution link to a more easily remembered link.
awswork.com will be the domain that will be resolved by the CloudFront link.
The zone is already configured in Amazon Route 53:
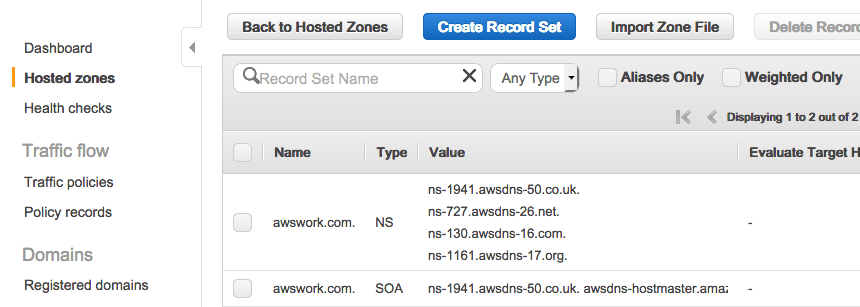
The purpose is to replace dwmm0kwdwl4fr.cloudfront.net with awswork.com:
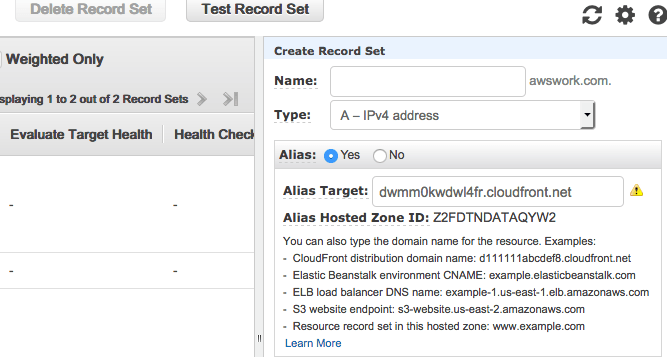
There is one extra step required for this to work and that is to configure the CNAME in CloudFront distribution.
Currently, this is empty:
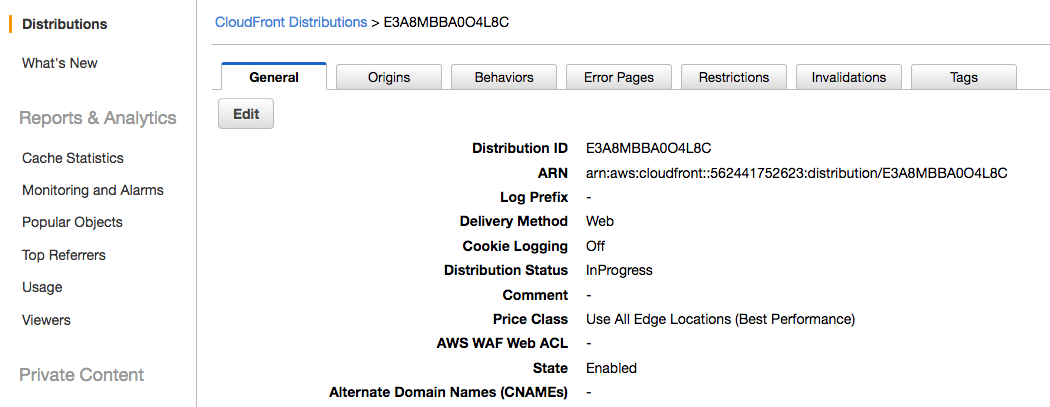
Remember that the CNAME has to match the A entry in Route 53 zone:
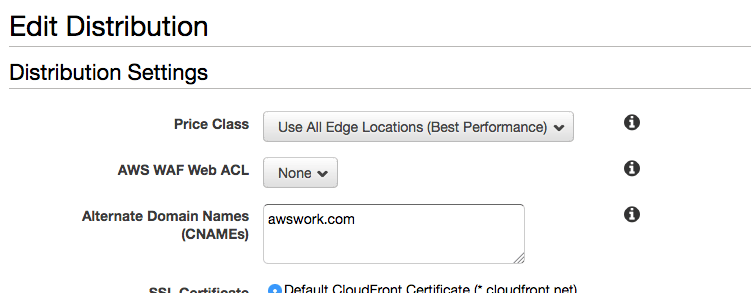
Once this is done, it is time to check if Route 53 direct the client to CloudFront that is retrieving the data from Azure storage containers.

And for .htm files:

And this would be all how to implement a solution using AWS and Azure services.
Throughout the post, we covered the basics of Azure blob storage, AWS CloudFront and Route 53. Finally, we saw how one can use different services from both cloud providers to implement a solution where data stored in one cloud provider is delivered to clients using services from the second one.
References:
- Naming and Referencing Containers, Blobs, and Metadata
- What Is Amazon CloudFront?
- Working with Distributions
- What Is Amazon Route 53?
- Configuring DNS to Route Traffic




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment