
This blog post is about the Read Replicas for Azure Database for PostgreSQL which Microsoft recently announced in a preview.
Azure Database for PostgreSQL now supports continuous, asynchronous data replication from the master Azure Database for PostgreSQL server to up to five Azure Database for PostgreSQL servers located in the same region. These read replicas allow scaling out the read-heavy workloads horizontally while balancing them across the replicas according to the user preferences. Replica servers are read-only except for the replications on the master. When the replication is off, the replica server acts as a standalone server that accepts reads and writes.
Replication functionality provides the following key features:
- Addition and deletion of replicas.
- Up to 5 read replicas are supported in the same region.
- Replication can be stopped anytime to make a replica a standalone, read-write server.
- Replication performance can be monitored using two metrics, Replica Lag and Max Lag
Below are some of the application patterns and reference architectures.
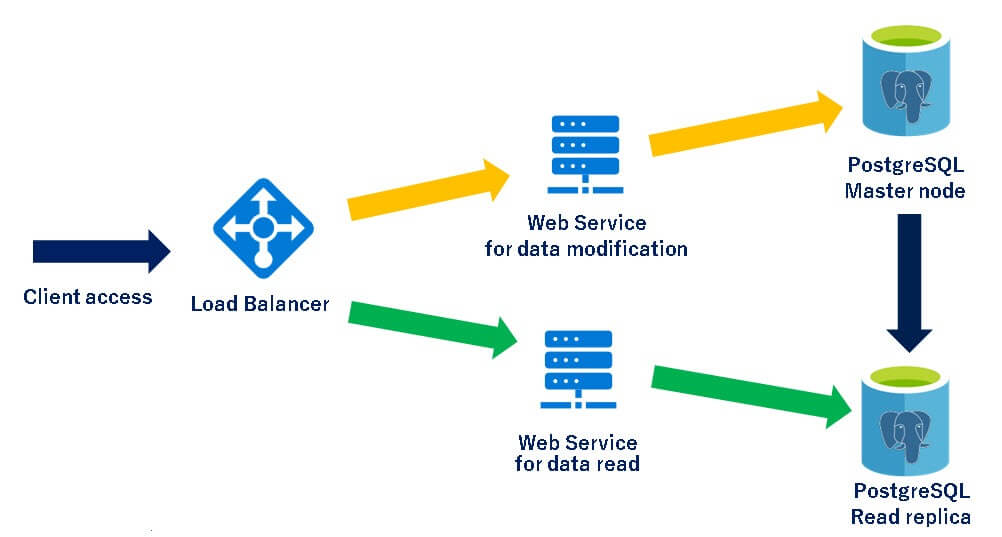
Microservices Pattern with Read scale Replicas
This architecture pattern breaks the application into multiple microservices where the data modification APIs connect to master server while the reporting APIs connect to read replicas. The data modification APIs are prefixed with “Set-” and reporting APIs are prefixed with “Get-“. The load balancer routes the traffic based on the API prefix:
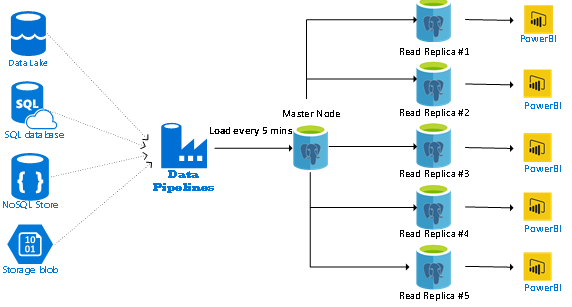
BI Reporting
In this architecture data from the different data sources is processed and loaded in the master server. The reporting workload is scaled across multiple read replicas to allow for high user concurrency with low latency. The master server dedicated for the workloads and processing does not directly expose them to BI users to provide predictable performance.
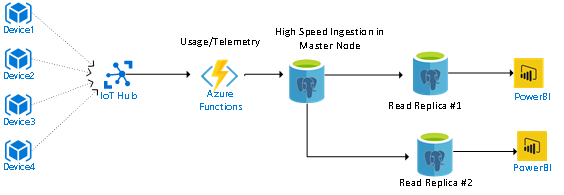
IoT scenario
Here is an example of IoT scenario. The streaming data is loaded in the master node as a persistent layer for high-speed data ingestion. The read replicas are leveraged for reporting and downstream data processing to take data-driven actions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment