Keeping VM Scale Sets performing optimally
For organizations utilizing Azure VM Scale Sets regular reboots can help mitigate common causes of performance degradation, such as memory leaks, connections that weren’t properly closed and disposed of, etc. Similar to ensuring stability for Azure Cloud Roles CloudMonix helps with automation of common tasks that keep VM Scale Sets performing optimally.
In this case study, we’ll discuss a few very simple approaches to keep your Azure VM Scale Sets stable proactively and reactively as well as saving costs with the proper management of the time an application is up and running.
Proactive stability – DAILY SCHEDULED REBOOTS
CloudMonix allows performing proactive daily reboots at a simple checkbox click. Read below >
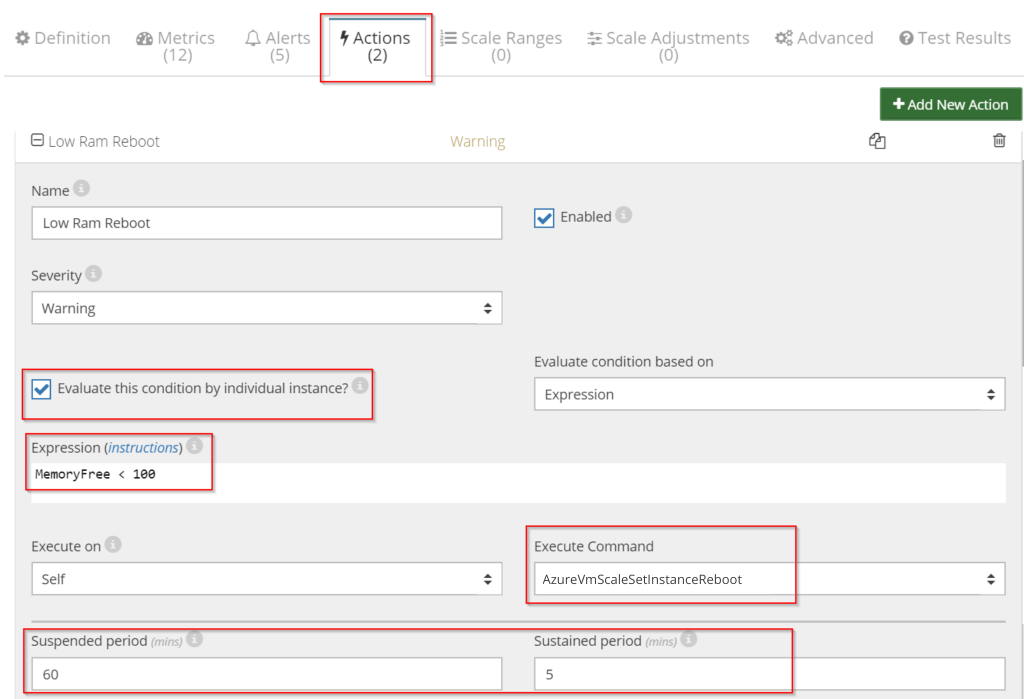
Reactive stability – REBOOTS ON DEMAND
CloudMonix allows for immediate and automatic recovery from such events via reboots on-demand. Read below >
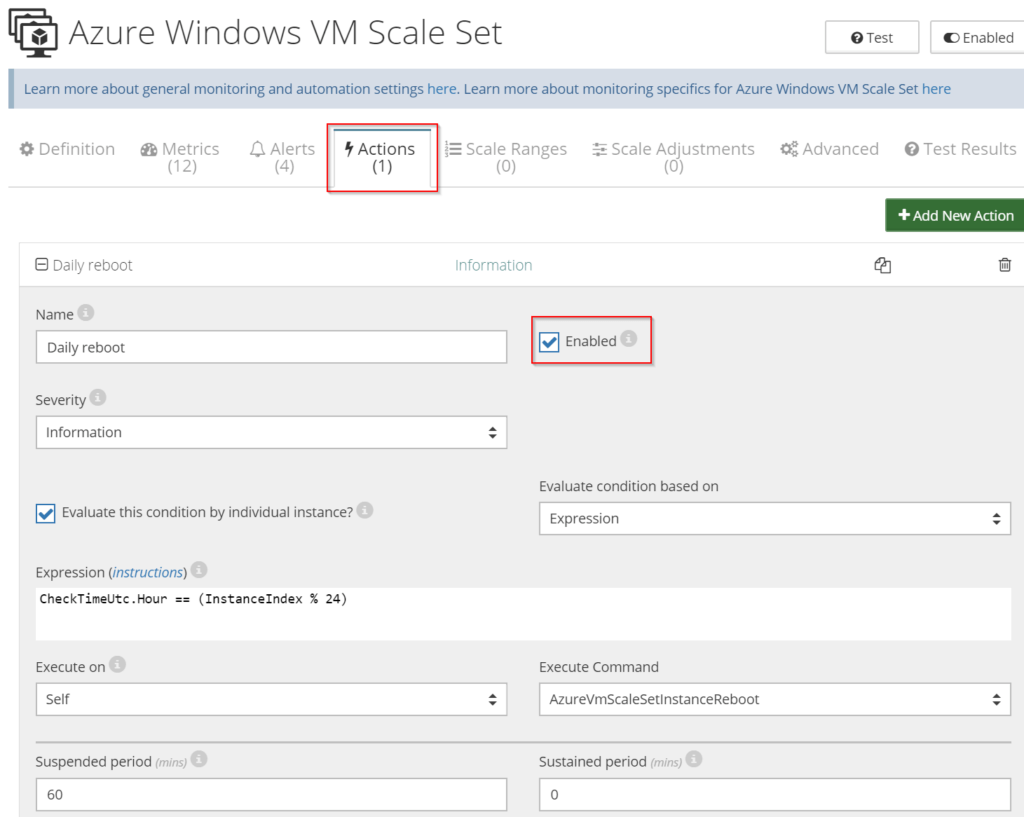
How to do daily reboots
In order to enable the “Daily Reboot” action complete the following steps:
- select your resource, go to Settings and select Actions tab;
- select the “Daily Reboot” action from the list of available default actions;
- check the “Enabled” checkbox to activate the action.
Rebooting of instances is done one-at-a-time, at the top of every hour, starting at UTC 0.00. Rebooting instances one at a time ensures that VM Scale Set continues to be up and running.
How to configure reboots on demand
Setting up an action that reboots an instance when available memory drops below some threshold for a sustained amount of time is trivial and takes a few seconds. This action is built-in into the default CloudMonix profiles as “Low Ram Reboot” and is disabled by default. In order to activate this action select the “Low Ram Reboot” action under “Actions” tab in instance settings and check the “Enabled” checkbox. Configure additional parameters as described in the picture.